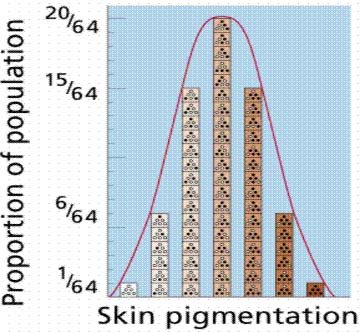
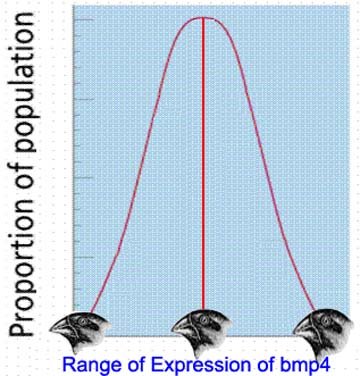
TITLE:
Genome 2.0: Mountains Of New Data Are Challenging Old ViewsAUTHOR: Patrick Barry
SOURCE:
Science NewsCOMMENTARY:
Allen MacNeillFirst, an introductory comment:
In a previous post (
New Definitions Of A Gene), I discussed new ideas of what genes might be according to recent discoveries in genetics and genomics. Now comes the absolutely stunning news that between 74% and 93% of the typical mammalian genome is transcribed into RNA, but not translated. This DNA accounts for almost all of what was recently referred to as "junk DNA." This discovery has shaken some of the fundamental principles of genetics, and promises to do even more to the underlying assumptions of neo-Darwinian evolutionary theory.
In particular, the "neutral theory" of Motoo Kimura and the "nearly neutral theory" of Tomoko Ohta may need to be extensively revised, if not entirely replaced. These theories are based on the assumption that the vast majority of the DNA of most organisms, especially eukaryotes, is selectively neutral (i.e. is not acted upon by natural selection). Furthermore, central to these theories is the idea that the neutrality of most of the genome is the result of its
not being transcribed or translated into protein (and therefore ultimately into some component of organisms' phenotypes). However, if most of this DNA
is transcribed, but not translated, then these theories (which form part of the foundation of current neo-darwinian evolutionary theory) will probably have to be revised, or even jettisoned.
Here is the text of the entire article. Pay particular attention to the various hypotheses presented for what all that transcribed but not translated RNA is doing in cells. This discovery opens up a huge new area of research, and seriously undermines the estimate of the number of "genes" mapped by the Human Genome Project:
***************************************************************************
When scientists unveiled a draft of the human genome in early 2001, many cautioned that sequencing the genome was only the beginning. The long list of the four chemical components that make up all the strands of human DNA would not be a finished book of life, but a road map of an undiscovered country that would take decades to explore.
Only 6 years later, the landscape of the genome is already proving to be dramatically different than most scientists had expected.
The established view of the genome began to take shape in 1958, just 5 years after Francis Crick and James D. Watson worked out the structure of DNA. In that year, Crick expounded what he called the "central dogma" of molecular biology: DNA's genetic information flows strictly one way, from a gene through a series of steps that ends in the creation of a protein. That principle developed into a modern orthodoxy, according to which a genome is a collection of discrete genes located at specific spots along a strand of DNA. This old view got the basics right: that genes encode proteins and that proteins do the myriad work necessary to keep an organism alive.
Researchers slowly realized, however, that genes occupy only about 1.5 percent of the genome. The other 98.5 percent, dubbed "junk DNA," was regarded as useless scraps left over from billions of years of random genetic mutations. As geneticists' knowledge progressed, this basic picture remained largely unquestioned. "At one time, people said, 'Why even bother to sequence the whole genome? Why not just sequence the [protein-coding part]?'" says Anindya Dutta, a geneticist at the University of Virginia in Charlottesville.
Closer examination of the full human genome is now causing scientists to return to some questions they thought they had settled. For one, they're revisiting the very notion of what a gene is. Rather than being distinct segments of code amid otherwise empty stretches of DNA—like houses along a barren country road—single genes are proving to be fragmented, intertwined with other genes, and scattered across the whole genome.
Even more surprisingly, the junk DNA may not be junk after all. Most of this supposedly useless DNA now appears to produce transcriptions of its genetic code, boosting the raw information output of the genome to about 62 times what genes alone would produce. If these active nongene regions don't carry code for making proteins, just what does their activity accomplish?
"What we thought was important before was really just the tip of the iceberg," says Hui Ge of the Whitehead Institute for Biomedical Research in Cambridge, Mass.
With the genome sequence in hand, exploration has moved at a brisk pace during the past 6 years. A milestone was reached in June, when a project called the Encyclopedia of DNA Elements (ENCODE) thoroughly mapped the functional regions in 1 percent of the human genome. The effort involved was staggering: Thirty-five teams of scientists from around the world worked for 4 years and compiled more than 600 million data points, the consortium reported in the June 14 Nature.
From the accumulating mountains of data, scientists are building a new picture of how the genome works as a whole. They have found mutations in nongene regions of DNA that are linked to common diseases such as diabetes and forms of cancer. And some researchers propose that DNA once labeled junk could have spawned the complex bodies of higher organisms—even the complexities of the human brain.
Second Fiddle To A Superstar
In the emerging picture of the genome's functioning, many of the key elements identified so far are molecules of RNA, a chemical cousin of DNA.
In the old central dogma, RNA had a strictly subservient role in the all-important task of making proteins. An RNA molecule is made from units of genetic code strung together, much like DNA. But while DNA has two strands twisted together into a double helix, RNA usually has only a single strand.
Protein synthesis begins when the two strands of a section of DNA unzip. Units of RNA then pair up with their counterparts on one of the DNA strands, forming a complementary messenger RNA (mRNA) molecule. The mRNA detaches and floats off to other parts of the cell, where it hooks up with machinery that transcribes its coded message into a protein.
If RNA's only job were making proteins, then nearly all the RNAs produced in cells should be transcripts of protein-coding genes. (A small fraction of RNAs serve in the protein-transcription machinery.) But in 2005, Jill Cheng and her colleagues at Affymetrix, a genomics company in Santa Clara, Calif., showed that less than half of the RNA produced by 10 of the chromosomes in human cells represented transcripts of traditional genes. In the team's experiments, 57 percent of the RNA was transcribed from noncoding, "junk" regions.
The results from ENCODE were even more striking. In the slice of DNA studied in that project, between 74 percent and 93 percent of the genome produced RNA transcripts. What becomes of this tremendous output is uncertain. John M. Greally of the Albert Einstein College of Medicine in New York says it's likely that some portion of it is made accidentally and simply discarded. But the discovery that so much of the genome is being transcribed into RNA underscores how out-of-date the central dogma has become.
Indeed, the closer researchers look, the more functions they find that RNA transcripts perform. An alphabet soup of new acronyms describes the newfound roles of RNAs. First there were short nuclear RNAs (snRNAs) and short nucleolar RNAs (snoRNAs), both of which reside inside the nucleus and help control production of other RNAs. These were joined by microRNAs (miRNAs) and short interfering RNAs (siRNAs), which can modulate the activity of protein-coding genes. In mice, about 34,000 of the RNA transcripts produced by the genome are nonprotein-coding, outnumbering the roughly 32,000 transcripts that code for proteins, according to a 2005 study by an international group of scientists called the Functional Annotation of Mouse Consortium.
These new families of RNAs add a layer of regulation that fine-tunes the production of proteins. While scientists already knew that some proteins influence the activity of other genes, "there are many more RNAs than proteins that play a regulatory role," Ge says.
Gene regulation may not sound sexy, but it's a powerful way for a cell to evolve complex behaviors using the tools—proteins—that it already has. Consider the difference between a one-bedroom bungalow and an ornate, three-story McMansion. Both are made from roughly the same materials—lumber, drywall, wiring, plumbing—and are put together with the same tools—hammers, saws, nails, and screws. What makes the mansion more complex is the way that its construction is orchestrated by rules that specify when and where each tool and material must be used.
In cells, regulation controls when and where proteins spring into action. If the traditional genome is a set of blueprints for an organism, RNA regulatory networks are the assembly instructions. In fact, some scientists think that these additional layers of complexity in genome regulation could be the answer to a long-standing puzzle.
Genome As Network
The biggest surprise in the first sequence of the human genome was how few protein-coding genes it contained.
"We humans do not have that many more genes than simpler organisms like flies or mice," Ge says. Earlier guesses of the number of genes in humans ran as high as 100,000, but the published sequence in fact contained only about 23,000. That's not much more than the roughly 21,000 genes possessed by the roundworm, a microscopic creature without a brain. If protein-coding genes are the only functional elements in an organism's DNA, where does the extra information come from that's needed to assemble and operate the complex bodies and brains of people, as compared with the simplicity of roundworms? "If we just look at the number of genes, it doesn't make sense," Ge says.
While the number of genes isn't much different in roundworms and people, the human genome is 30 times the size of the roundworms'. People have a much larger quantity of DNA beyond what codes for proteins. Since much of this "junk" DNA is being transcribed into RNA, perhaps it's responsible for much of the complexity of human bodies and brains. In fact, organisms simpler than roundworms, such as single-celled bacteria, carry little noncoding DNA and may have no regulatory RNA at all.
"Scientists have been suspecting that it is the regulatory networks that lead to this amazing complexity" in higher organisms, Ge says.
John S. Mattick of the University of Queensland in Brisbane, Australia, points to a known example of the importance of regulatory RNAs: their crucial role in fetal development. For example, most multicellular animals possess a gene called Notch that helps guide neural development. While the gene itself has much the same form in both simple and complex animals, its activity is regulated by miRNAs that are highly variable from one animal to another. Such miRNAs also influence a gene called Hox, which acts in many animals to define a fetus' body axis and the placement of its limbs.
What's more, the changes that distinguish human brains from those of chimpanzees and other apes could be due in part to evolutionary changes in RNAs that don't encode proteins. A group led by Katherine S. Pollard of the University of California, Davis identified DNA sequences shared by people and chimpanzees, but with large differences, meaning that they have evolved rapidly since the two species shared a common ancestor.
The researchers found that one of these sequences is a noncoding region of DNA that's related to brain function, they reported in the Sept. 14, 2006 Nature. Pollard and her colleagues speculate that this region produces a regulatory RNA and that changes in this RNA contributed to the evolution of the human brain.
With regulatory RNAs appearing to play such an instrumental role in animal development, it's no surprise that scientists are finding disease-associated mutations in regions of the genome formerly regarded as junk.
David Altshuler of the Broad Institute in Cambridge, Mass., and his colleagues looked for DNA mutations in 1,464 patients with type 2 diabetes. Three of the mutations that correlated with the disease were in DNA segments that don't code for proteins, the team reported in the June 1 Science. Other scientists have found mutations in noncoding DNA that link to diseases such as autism, breast cancer, lung cancer, prostate cancer, and schizophrenia.
To be sure, the specific functions of most of the noncoding DNA remain unknown. Projects such as ENCODE have focused on identifying the broad functional categories for active regions of the genome without working out the specific cellular function of each transcript, a task that will take biologists years, if not decades.
In fact, scientists debate whether some fraction of the genome's copious RNA output might do nothing at all. It may simply be that once the cellular machinery that transcribes DNA into RNA gets started, it sometimes doesn't know when to stop. On the other hand, making lots of RNA that does nothing would be a waste of a cell's energy. That's something that natural systems tend to avoid, so the fact of its production argues for at least some of this RNA being biologically active.
The Gene Is Dead
In the old view, each gene sat in splendid isolation on its segment of the genome. Other genes might be nearby, but scientists assumed that they didn't overlap each other.
Now it's clear that a single length of DNA can be transcribed in multiple ways to produce many different RNAs, some coding for proteins and others constituting regulatory RNAs. By starting and stopping in different places, the transcription machinery can generate a regulatory RNA from a length of DNA that overlaps a protein-coding gene. Moreover, the code for another regulatory RNA might run in the opposite direction on the facing strand of DNA. According to the ENCODE project results, up to 72 percent of known genes have transcripts on the facing DNA strand as well as the main strand.

"The same sequences are being used for multiple functions," says Thomas R. Gingeras of Affymetrix. That introduces complications into the evolution of the genome, which had until recently been assumed to act through single DNA mutations affecting single genes. Now, "a mutation in one of those sequences has to be interpreted not only in terms of [one gene], but [of] all the other transcripts going through the region," Gingeras explains.
The implications of this single mutation–multiple consequence model are still a matter of debate. In some cases, the RNA transcripts from DNA that overlaps a protein-coding gene regulate that same gene, so a mutation could affect both the structure and the regulation of a protein. But often, those transcripts regulate genes that are far away, or even on different chromosomes. This complex interweaving of genes, transcripts, and regulation makes the net effect of a single mutation on an organism much more difficult to predict, Gingeras says.
More fundamentally, it muddies scientists' conception of just what constitutes a gene. In the established definition, a gene is a discrete region of DNA that produces a single, identifiable protein in a cell. But the functioning of a protein often depends on a host of RNAs that control its activity. If a stretch of DNA known to be a protein-coding gene also produces regulatory RNAs essential for several other genes, is it somehow a part of all those other genes as well?
To make things even messier, the genetic code for a protein can be scattered far and wide around the genome. The ENCODE project revealed that about 90 percent of protein-coding genes possessed previously unknown coding fragments that were located far from the main gene, sometimes on other chromosomes. Many scientists now argue that this overlapping and dispersal of genes, along with the swelling ranks of functional RNAs, renders the standard gene concept of the central dogma obsolete.
Long Live The Gene
Offering a radical new conception of the genome, Gingeras proposes shifting the focus away from protein-coding genes. Instead, he suggests that the fundamental units of the genome could be defined as functional RNA transcripts.
Since some of these transcripts ferry code for proteins as dutiful mRNAs, this new perspective would encompass traditional genes. But it would also accommodate new classes of functional RNAs as they're discovered, while avoiding the confusion caused by several overlapping genes laying claim to a single stretch of DNA. The emerging picture of the genome "definitely shifts the emphasis from genes to transcripts," agrees Mark B. Gerstein, a bioinformaticist at Yale University.
Scientists' definition of a gene has evolved several times since Gregor Mendel first deduced the idea in the 1860s from his work with pea plants. Now, about 50 years after its last major revision, the gene concept is once again being called into question.
REFERENCES CITED:
Cheng, J. . . . and T.R. Gingeras. 2005. Transcriptional maps of 10 human chromosomes at 5-nucleotide resolution. Science 308(May 20):1149-1154. Available at http://www.sciencemag.org/cgi/content/full/308/5725/1149.
Chopra, V.S., and R.K. Mishra. 2006. "Mir"acles in hox gene regulation. Bioessays 28(May):445-448. Abstract available at http://dx.doi.org/10.1002/bies.20401.
Claverie, J.-M. 2005. Fewer genes, more noncoding RNA. Science 309(Sept. 2):1529-1530. Abstract available at http://www.sciencemag.org/cgi/content/abstract/309/5740/1529.
Diabetes Genetics Initiative of Broad Institute of Harvard and MIT, Lund University, and Novartis Institutes of BioMedical Research. 2007. Genome-wide association analysis identifies loci for type 2 diabetes and triglyceride levels. Science 316(June 1):1331-1336. Abstract available at http://www.sciencemag.org/cgi/content/abstract/316/5829/1331.
Gerstein, M.B., et al. 2007. What is a gene, post-ENCODE? History and updated definition. Genome Research 17(June):669-681. Available at http://www.genome.org/cgi/content/full/17/6/669.
Gingeras, T.R. 2007. Origin of phenotypes: Genes and transcripts. Genome Research 17(June):682-690. Available at http://www.genome.org/cgi/content/full/17/6/682.
Kapranov, P. . . . and T.R. Gingeras. 2007. RNA maps reveal new RNA classes and a possible function for pervasive transcription. Science 316(June 8):1484-1488. Abstract available at http://www.sciencemag.org/cgi/content/abstract/316/5830/1484.
______. 2002. Large-scale transcriptional activity in chromosomes 21 and 22. Science 296(May 3):916-919. Available at http://www.sciencemag.org/cgi/content/full/296/5569/916.
Mattick. J.S. and I.V. Makunin. 2006. Non-coding RNA. Human Molecular Genetics 15(April 15):R17-R29. Available at http://hmg.oxfordjournals.org/cgi/content/full/15/suppl_1/R17.
Mattick, J.S. 2005. The functional genomics of noncoding RNA. Science 309(Sept. 2):1527-1528. Abstract available at http://www.sciencemag.org/cgi/content/abstract/309/5740/1527.
______. 2004. RNA regulation: A new genetics? Nature Reviews Genetics 5(April):316-323. Abstract available at http://dx.doi.org/10.1038/nrg1321.
Moore, M.J. 2005. From birth to death: The complex lives of eukaryotic mRNAs. Science 309(Sept. 2):1514-1518. Abstract available at http://www.sciencemag.org/cgi/content/abstract/309/5740/1514.
Pollard, K.S., et al. 2006. An RNA gene expressed during cortical development evolved rapidly in humans. Nature 443(Sept. 14):167-172. Abstract available at http://dx.doi.org/10.1038/nature05113.
Prasanth, K.V., and D.L. Spector. 2007. Eukaryotic regulatory RNAs: An answer to the 'genome complexity' conundrum. Genes and Development 21(Jan. 1):11-42. Available at http://www.genesdev.org/cgi/content/full/21/1/11.
Strausberg, R.L., and S. Levy. 2007. Promoting transcriptome diversity. Genome Research 17(July):965-968. Abstract available at http://www.genome.org/cgi/content/abstract/17/7/965.
The ENCODE Project Consortium. 2007. Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project. Nature 447(June 14):799-816. Available at http://dx.doi.org/10.1038/nature05874.
Wienholds, E., and R.H.A. Plasterk. 2005. MicroRNA function in animal development. FEBS Letters 579(Oct. 31):5911-5922. Available at http://dx.doi.org/10.1016/j.febslet.2005.07.070 .
Weinstock, G.M. 2007. ENCODE: More genomic empowerment. Genome Research 17(June):667-668. Available at http://www.genome.org/cgi/content/full/17/6/667.
Willingham, A.T., and T.R. Gingeras. 2006. TUF love for "junk" DNA. Cell 125(June 30):1215-1220. Available at http://dx.doi.org/10.1016/j.cell.2006.06.009.
Zamore, P.D., and B. Haley. 2005. Ribo-gnome: The big world of small RNAs. Science 309(Sept. 2)::1519-1524. Abstract available at http://www.sciencemag.org/cgi/content/abstract/309/5740/1519.
Further Readings:
Bower, B. 2006. Evolution's DNA difference: Noncoding gene tied to origin of human brain. Science News 170(Aug. 19):116. Available to subscribers at http://www.sciencenews.org/articles/20060819/fob4.asp.
Hesman, T. 2000. The meaning of life. Science News 157(April 29):284-285. Available at http://www.sciencenews.org/articles/20000429/bob9.asp.
Travis, J. 2002. Biological dark matter. Science News 161(Jan. 12):24-25. Available at http://www.sciencenews.org/articles/20020112/bob9.asp.
SOURCES:
David P. Bartel
Whitehead Institute
Nine Cambridge Center
Cambridge, MA 02142
George Church
Harvard Medical School
Genetics NRB Room 238
77 Avenue Louis Pasteur
Boston, MA 02115
Anindya Dutta
University of Virginia Health System
P.O. Box 800733
Charlottesville, VA 22908
Hui Ge
Whitehead Institute
Nine Cambridge Center
Cambridge, MA 02142
Mark B. Gerstein
Yale University
266 Whitney Avenue
New Haven, CT 06511-8902
John M. Greally
Albert Einstein College of Medicine
Jack and Pearl Resnick Campus
1300 Morris Park Avenue
Ullmann Building, Room 911
Bronx, NY 10461
James Keesling
University of Florida
358 LIT
Gainesville, FL 32611
Elliott H. Margulies
Genome Technology Branch
National Human Genome Research Institute
Bethesda, MD 20892-8004
Zhiping Weng
Boston University
44 Cummington Street
Boston, MA 02215
Labels: gene definitions, genetic variation, junk DNA, non-transcribed DNA, regulatory DNA